Reliable agents need clear boundaries. We’ve expanded Guardrails settings to give you more control over what agents can process, generate, and act on. And the best part - they are super easy to enable, with just one click.
Expanded guardrail coverage
Guardrails now include configurable detection for, PII exposure, Prompt injection attempts, and allows you to specify which OpenAI moderation categories should be blocked by the guardrails settings (see the categories in the OpenAI moderation docs).
These checks run during execution and apply consistently across agent execution, from any agent invocation option on the platform.
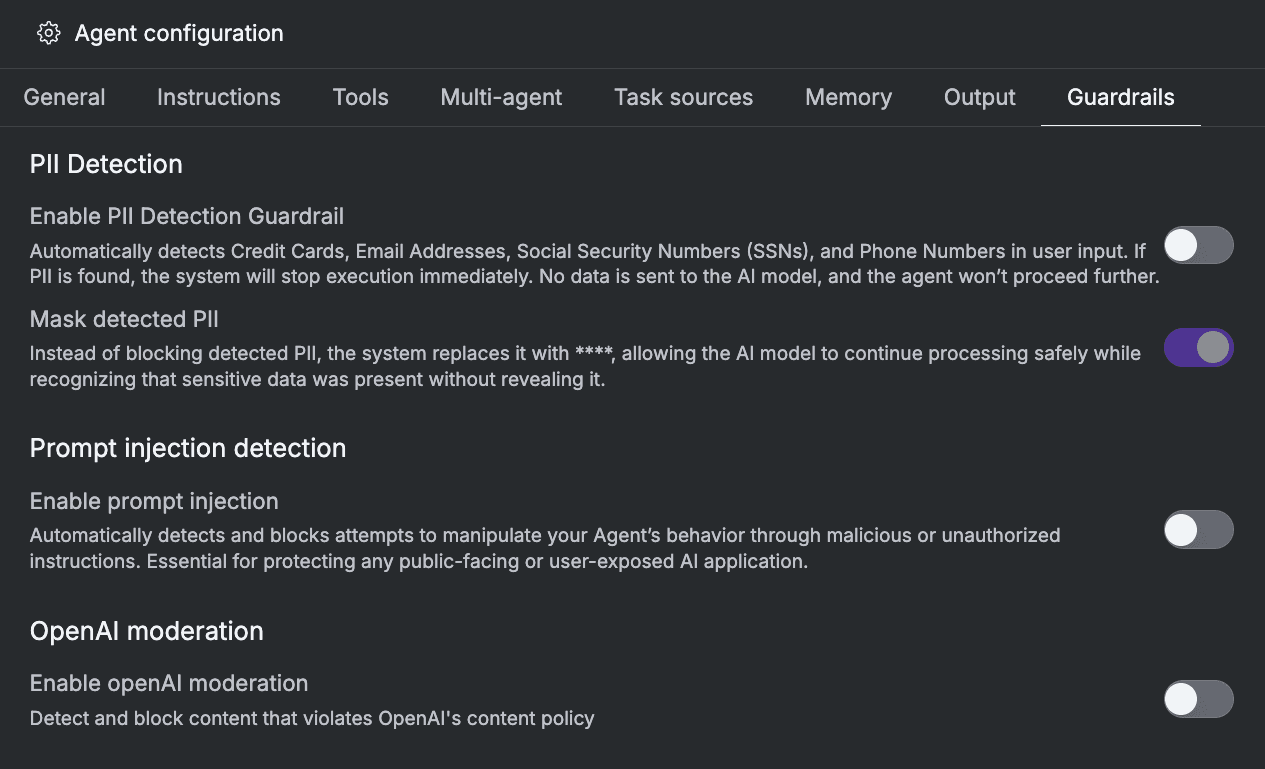
You can configure Guardrails from the Agent Workbench, depending on your individual agent requirements.


