

Building AI agents that can seamlessly interact with real-world tools and data is one of the hardest challenges in modern LLM infrastructure. At xpander.ai, this challenge is our daily bread and butter. We’ve spent countless hours enabling large language models (LLMs) to perform multi-step tasks across SaaS APIs, internal databases, and other systems. When Anthropic open-sourced the Model Context Protocol (MCP) late last year, we immediately saw its significance. MCP promised a standardized way for AI assistants to connect to the systems where data lives – a sort of “USB-C port” for AI applications. In theory, it could replace a tangle of bespoke integrations with a universal, two-way interface.
But theory only takes you so far. Implementing MCP at scale – in a production SaaS platform serving enterprise-grade AI agents – is another story entirely. As a founding engineer at a startup tackling this head-on, I’d like to share our journey adopting MCP and allowing our users to use MCP as a service all across the platform: the architectural decisions, the gritty engineering challenges (from Server-Sent Events streaming to multi-tenant security), and how we wove MCP into xpander.ai’s agent platform. This post will dive into how xpander exposes MCP through our agents and interfaces, how we handle tool schemas and validation, and why we even built our own xpander-mcp-remote CLI to bridge secure remote connections. Along the way, I’ll contrast MCP with other approaches (like OpenAI’s tool calling and LangChain agents) and explain why we believe MCP is a big deal for the future of AI interoperability.
What is the Model Context Protocol (MCP) and Why It Matters
MCP is an open standard introduced by Anthropic to let AI models connect with external tools, data sources, and environments in a consistent way. Instead of each integration requiring custom code or unique APIs, an AI assistant (like Claude or ChatGPT) can speak a common language to any MCP-compatible service. Think of how USB-C standardized device connections; MCP aspires to do the same for AI-tool integrations (. From a technical standpoint, MCP defines a simple client-server model: AI hosts (the LLM applications) act as clients that initiate connections, and MCP servers provide capabilities or data. Communication is done via JSON-RPC 2.0 messages over a transport channel. In plain English, the AI sends JSON-formatted “requests” to call a tool or fetch some context, and the server returns JSON “responses” with results (or streams of results). This JSON-RPC design is reminiscent of the Language Server Protocol from the IDE world – a deliberate inspiration to make AI-tool interactions composable and standardized across ecosystems.
Why does this matter? Because even the most advanced LLMs are often trapped in silos. They can’t fetch fresh data from your database or take action in your business software without custom plumbing. Every new integration has historically been an ad-hoc project. MCP aims to flip that script. With a universal protocol, the community can build and share connectors to databases, SaaS APIs, operating system functions, you name it. An AI agent could maintain context across different tools and datasets more naturally, instead of the fragmented function-call integrations we have today. This has big implications: it could standardize “tool use” for AI much like HTML standardized content for browsers. In fact, we’re already seeing convergence – OpenAI announced support for MCP in its own Agents SDK, and Microsoft is building real-world infrastructure on it as well (5). When multiple AI platforms rally around a standard, it’s a sign that MCP isn’t just hype but an emerging backbone for agent interoperability.
From xpander’s perspective, embracing MCP aligns perfectly with our philosophy of provider-agnostic, flexible AI integration. We’ve built our platform to avoid vendor lock-in (run with OpenAI, Anthropic, etc.) and to connect agents with any system. An open protocol like MCP is the next logical step: it lets our agents interface with third-party AI assistants on one side and with a plethora of tools on the other, in a uniform way. But to really leverage MCP, we had to get our hands dirty and make it work in practice. Let’s talk about how MCP actually operates under the hood and what it took to implement it in a scalable, secure manner.
Inside the MCP Architecture: JSON-RPC, Tools, and Streaming
At its core, the Model Context Protocol is straightforward: the AI client opens a connection to an MCP server, discovers what “tools” or data the server offers, and starts sending JSON-RPC calls. Each tool is essentially a remote function the AI can invoke. For example, a server might expose a tool like send_email or query_database with a defined schema for its inputs and outputs. The AI doesn’t need to know the low-level details of how that tool works – just the name, parameters, and expected result format. This is very analogous to OpenAI’s function calling interface, except that with MCP the implementation of the function lives outside the model’s API (it lives in the MCP server).
One key aspect of MCP is that it supports streaming responses and incremental updates via Server-Sent Events (SSE) transport. In practice, there are a couple of transport options: for local tools, an LLM might spawn the tool process and communicate over stdin/stdout (stdio transport). But for remote tools (like a cloud service), the typical method is HTTP + SSE. This works by the client (say Claude Desktop or another agent host) making an HTTP GET request to a special SSE endpoint on the MCP server to listen for events, and using a complementary HTTP POST endpoint to send commands to the server. The persistent SSE connection lets the server push streaming results back to the AI in real-time. For example, if a tool is performing a long-running database query, it can stream partial progress or chunked results to the LLM so the model can start formulating a response without waiting for the entire operation to complete. SSE is unidirectional (server-to-client) for streaming, but combined with the POST channel, it achieves a full two-way communication.
In an MCP session, the typical flow is: the AI client connects and maybe sends an initial “discover” or handshake request (JSON-RPC call to list available tools and resources). The server responds with its capabilities – essentially a list of tools with their schemas and any other context it provides. From then on, the AI can invoke those tools by sending a JSON-RPC request with the method name (tool name) and parameters. The server executes the tool’s code (which might call an external API or database on behalf of the AI) and returns the result as a JSON-RPC response. If the result is large or the action emits multiple outputs, the server might stream multiple partial responses as SSE events. The protocol also defines some utility methods like ping (health check), cancel (to abort a long tool call), and even logging or progress notifications.
All of this provides a structured, controlled way for an AI agent to do things in the world. But making it robust for real-world use is where the fun begins. At xpander, we needed to integrate MCP into our platform of managed agents and connectors.
Several engineering challenges head-on:
- Server-Sent Events at Scale: How to manage potentially thousands of long-lived SSE connections reliably.
- Multi-Tenancy and Security: How to isolate and secure each client’s tools and data in a multi-user environment.
- Tool Schema Registration: How to automatically register and expose our existing “tools” (integrations) via MCP in a way that’s easily consumable by any AI client.
- Input/Output Validation: How to ensure the AI’s JSON-RPC calls are correct and safe, given the notorious tendency of LLMs to hallucinate or format data incorrectly.
- Cross-System Orchestration: How to coordinate complex workflows that involve multiple tools or multi-step processes through the MCP interface without confusing the AI or sacrificing reliability.
We’ll examine each of these in turn, and explain the design decisions we made to address them.
Challenges of Implementing MCP in a Production Platform
Handling Streaming with Server-Sent Events (SSE)
SSE is a lightweight and elegant solution for streaming, but it comes with practical considerations. In a cloud environment, every SSE client means an open HTTP connection held open indefinitely. When you have a handful of users, that’s no problem; when you have hundreds or thousands, you need to ensure your server and network stack can handle a large number of concurrent open streams. We had to fine-tune our infrastructure (load balancers, timeouts, thread or async handlers) to support many idle-but-open SSE connections. Unlike a typical REST API where each request is quick and then gone, an SSE connection can last hours. We implemented heartbeat mechanisms and careful error handling to make SSE robust – for instance, detecting dropped connections and cleaning them up, or having the client auto-reconnect if either side experiences a hiccup. The MCP spec itself emphasizes proper lifecycle management and resource cleanup as a best practice, and we learned why: if you don’t close or reconnect cleanly, you end up with “ghost” sessions or resource leaks.
Another challenge was ensuring timely delivery of events. SSE delivers events in order, which is great, but if a client falls behind (e.g. network slowdown) it could delay subsequent messages. We put in place backpressure handling – if an SSE client isn’t keeping up consuming events, we may need to slow down or buffer on our side. In extreme cases, we’d rather drop a non-critical notification than block a critical one. These are the kind of nitty- gritty details that don’t show up in the shiny demo of MCP, but absolutely matter for a smooth user experience.
Finally, streaming adds complexity to multi-step tool calls. Imagine an AI calls a tool that itself triggers sub-operations; we might stream interim results (like partial data from one API before moving to the next). We had to decide how to partition streaming responses in a way that the AI (the client) understands which tool call they belong to. JSON-RPC gives each request an id so we can tag events with the corresponding request ID, ensuring even interleaved streams don’t get mixed up. In summary, we treated SSE connections as first- class citizens in our architecture, doing the hardening necessary for cloud scale (as any high-traffic WebSocket or SSE service requires), including timeouts, retries, and graceful fallbacks.
Multi-Tenancy and Isolation
xpander.ai is a multi-tenant platform – each user (or team) may have their own set of agents, connectors, and data. Exposing those via MCP meant we needed a strategy to securely segregate each tenant’s MCP endpoints. We obviously cannot have a single MCP server instance serve tools from multiple customer accounts without strong isolation, or we’d risk a privacy disaster. Our approach was to spin up logical MCP “servers” on a per- agent or per-integration basis, each identified by a unique URL containing an embedded API key or token. In practice, when you configure an integration (say a Slack connector) in xpander and enable MCP, our backend generates an MCP entry point URL that looks something like:
https://mcp.xpander.ai/<AGENT_OR_INTERFACE_ID>/<SECRET_TOKEN>This URL is essentially the address of your personal MCP server for that integration. We include a secret token in it (a long random string or API key) that the server uses to authenticate the caller.
Possession of that URL is what grants access, so we treat it like a password – it’s shown to you once in our UI when you set up the integration, and you should keep it safe (The MCP URL contains your API key, so never share it publicly. Treat it as a sensitive credential). When an AI client connects via that URL, we map it to your specific tools and data on the backend.
With this design, each user and each agent sees only their own connectors and actions. Even though behind the scenes many of those MCP endpoints might be served by the same cluster of servers, our software isolates their contexts completely. It’s analogous to how a cloud database service might give you a unique connection string for your database – even if it’s on a shared host, only you can access your slice. We also leverage tenant IDs in our logging and monitoring, so we can trace any request back to the originating account for auditing. This was non-trivial to implement because the MCP protocol itself is agnostic about multi-tenancy; it just defines the message passing. We had to layer our own authentication and routing on top of it. Thankfully, the MCP spec is adding a formal OAuth 2.1-based authorization framework in the latest revision (5), which we plan to adopt when clients support it and it will become stable. For now, the unique URL token approach, combined with HTTPS and our backend checks, provides the security our users need.
Another aspect of multi-tenancy is rate limiting and abuse prevention. If one user’s agent code goes haywire and starts spamming tool calls, we don’t want it to degrade service for others. We implemented per-token rate limits on MCP requests and put safeguards so one user can’t exhaust all server-side threads with extremely long-running tasks. These are the kinds of protections that an enterprise-ready platform needs to have in place when exposing something like MCP to the open world.
Tool Schema Registration and Versioning
For MCP to be useful, the AI client needs to know what tools are available and how to call them. In MCP’s terminology, this is often handled by the server advertising its capabilities or an openRPC schema. In our case, xpander already had the concept of Agentic Interfaces (tools/connectors) each defined by an internal schema (very similar to an OpenAI function spec). For example, our Gmail connector has an action send_email to, subject, body, etc., each with certain types or allowed formats. Adapting them to MCP was relatively straightforward: we translate our internal schema format into the JSON schema syntax expected by MCP JSON-RPC. Essentially, when an AI client asks our MCP endpoint “what methods do you have?”, we respond with a list of methods and their parameter schema, description, etc., drawn from the same definitions that power our platform’s function calling. This dual-use of schemas ensures consistency – whether an agent is running inside xpander or an AI is calling via MCP, the definition of send_email or create_ticket is the same.
That said, maintaining these schemas over time is a chore. APIs change, we improve descriptions, add new optional parameters, deprecate others. We built a tool registry system internally where each integration’s schema is versioned. When we deploy an update to a connector (say we add a new action or change a field), the MCP server for that connector can advertise a new version in its capability response. We decided to keep things simple for now: our MCP endpoints always expose the latest version of a tool’s capabilities, under the assumption that both our backend and the AI using it should be kept up-to-date. (If a breaking change occurs, we coordinate it as a product update to users.) In the future, we may leverage the MCP spec’s version negotiation features so that clients could specify a version or handle compatibility more gracefully.
One interesting nuance was how to present complex tools to the LLM. Some of our integrations are relatively simple (one-call actions), but others are complex sequences. For example, consider a database query tool where the AI first needs to call a list_tables method, then a query_table We have to expose all those sub-methods. We make sure to provide helpful descriptions and even usage examples in the metadata so that the model can figure out the right sequence. Experience taught us that the quality of tool descriptions and schemas directly impacts the model’s success in using them. A small ambiguity can lead the LLM to construct an invalid payload. Even with clear schemas, LLMs sometimes produce imperfect API calls – which brings us to validation.
Input Validation and Error Handling
Anyone who has tried OpenAI’s function calling or similar will know that models aren’t infallible in formatting their outputs. They might omit a required field, use an incorrect data type, or misunderstand an error message. We saw the same with MCP. The difference with MCP is that the execution of the tool is happening outside the model’s context (in our server), so we must validate the request payloads carefully before executing anything. Our MCP server performs a multi-layer validation on every incoming JSON-RPC request: first it checks JSON schema validity (are all required parameters present? do types match? enums within allowed set, etc.). This catches the obvious mistakes. But we didn’t stop there. We also added semantic validation where appropriate. For instance, if the tool is create_notion_page and the model provided property_name that doesn’t actually exist in the target Notion database, we can detect that by a pre-flight check against the actual system (or a cached schema of the user’s Notion DB) and return a clear error to the AI before even attempting the call. This is important because the model might produce something that is technically well-formed JSON yet semantically incorrect for the task. As we noted in an earlier blog post, even a perfectly structured output can fail if the content doesn’t match the real API’s expectations (e.g. using "title" instead of the actual field name "name" in a Notion API call) (4). Our job on the MCP server side is to catch those and signal back to the model, ideally with a helpful error message.
We leverage JSON-RPC’s error response format to do this. If validation fails, we return an error object with a message explaining the issue. For example, “Error: ‘title’ is not a recognized field; did you mean ‘name’?” in the Notion scenario. The nice thing is LLMs are pretty good at reading error messages and adjusting their next attempt accordingly (Claude and GPT-4 certainly are). By iterating this way, the AI can usually self-correct and succeed on the second try. This dynamic is crucial for letting the AI figure out how to use complex tools – it’s not unlike a human learning an API by seeing error responses.
On the output side, validation is also important. We ensure the data we send back conforms to the schema we promised. This might involve sanitizing or transforming results from an external API. For example, if an API returns a numeric code where our schema says status: "success" | "fail", we translate that code into one of the expected strings so the model only sees the format it was told to expect. Consistency here means the model doesn’t get confused by out-of-schema surprises. And if for some reason our tool encounters an unexpected situation (e.g. a network timeout contacting a third-party service), we also package that as a proper JSON-RPC error so that the model knows the tool didn’t complete. This avoids a class of issues where the model might be left waiting or guessing. Overall, rigorous validation and error handling have been key to making MCP usable in practice. It turns the wild, unconstrained outputs of an LLM into a disciplined conversation between the AI and our tools. In effect, we’re providing the guardrails that keep the agent from driving off the road when it comes to tool use. The result is more reliable autonomous agents – something we’ve quantified before (our structured approach improved multi-step success rates dramatically)
Orchestrating Cross-System Workflows
A major appeal of xpander’s platform is that an agent can orchestrate multi-step workflows involving several different tools. For instance, “When a new lead appears in Salesforce, cross-reference it with our product database, then send a Slack alert and create a task in Asana.” That might involve 7-10 distinct API calls across systems. Now, if you give an LLM all those tools via MCP and just say “have at it,” it might figure it out… or it might flounder. One of the hard truths of autonomous agents is that the more tools you provide, the more combinatorial complexity the poor model has to reason about. We’ve found that beyond a handful of tools, success rates drop sharply (4). So, how do we enable cross-system magic without overloading the AI?
Our solution inside xpander has been to introduce an Agent Graph System (AGS) – essentially a directed graph that can orchestrate calls in a controlled fashion. Think of it as a smart wrapper that can guide the LLM: at a given step, only certain tools or sequences are allowed, and state from previous steps is stored and passed along. When exposing capabilities via MCP, we have two modes:
Expose each tool individually: This is the straightforward approach where the AI (e.g. Claude) sees “Slack.send_message”, “Salesforce.get_lead”, “Asana.create_task” as separate actions. The AI can decide to call them in whatever order. This maximizes flexibility but as mentioned, can be brittle if the sequence is complex.
- Exposing entire agents as MCP servers is a powerful pattern. In xpander, you can indeed treat a whole agent (with its multiple steps and logic) as a single MCP endpoint. This means the AI client doesn’t need to micromanage each sub-tool; it delegates a chunk of work to xpander’s orchestrator. We carefully document to the user (and by extension to the LLM via descriptions) what that one “mega-tool” will do. For instance: “
handle_new_deal: automates the new lead processing by cross-checking internal DB and notifying Sales via Slack.” The LLM can then decide if and when to use that capability, rather than juggling 3-4 discrete calls on its own.
We still support the fine-grained approach when needed (single MCP Server and cherry-picking API operations). But having the option to encapsulate multi-step workflows into a domain specific agent has been a game changer for reliability. It’s very analogous to how high-level APIs increase success by doing more behind the scenes. We’re basically raising the abstraction level of the tools when appropriate and still keeping the autonomy of the AI Agent. And thanks to MCP’s flexibility, whether we present 10 separate tools or 1 composite tool, it’s just a matter of what we advertise in the server’s capabilities. The protocol doesn’t constrain it – we do, based on what yields better outcomes.
xpander.ai’s MCP Integration demo: Agents, Interfaces, and Entry Points
With the challenges addressed (or at least mitigated), how does all this come together in xpander.ai’s product? Let’s walk through what happens when an xpander user wants to use MCP:
- Enabling MCP for an Agent or Integration: In our web console, the user can navigate to their Agentic Interfaces settings. Here they see all the connectors (integrations) they have set up – e.g. Gmail, LinkedIn, Slack, HubSpot, internal APIs, etc. Each of these has an option to “MCP Configuration”. We also allow enabling MCP on an entire agent (which might encompass multiple tools). When they enable it, we generate the unique MCP endpoint URL (entry point) for that specific interface or agent. This is shown to the user, and they are instructed to plug it into their chosen AI client. For example, if using Claude Desktop, they’d add an entry in the
claude_desktop_config.jsonwith a name and the command to run our CLI with that URL. If using another client (say an IDE like Cursor or Visual Studio Code with an AI plugin), a similar config is added. - Using
xpander-mcp-remoteCLI – Today, many AI clients (Claude Desktop, Cursor, etc.) assume MCP servers will run locally. They typically want to execute a command on your machine that starts the MCP server. Obviously, our xpander MCP server is running in the cloud, not on your laptop.xpander-mcp-remoteis a small Node.js CLI tool (available vianpx) that acts as a bridge between local and remote. When Claude Desktop launches it for, say, the “slack” integration, the CLI connects tohttps://mcp.xpander.ai/your-slack-urlusing the SSE transport and then presents a local stdio interface to Claude. In essence, to Claude it looks like it’s talking to a local process (over stdio), but in reality that process is piping everything over the internet to xpander’s servers. This trick allows existing MCP clients (which don’t yet natively support remote HTTP+SSE with auth) to connect to cloud-hosted tools (mcp-remote – npm).
The need for xpander-mcp-remote arose from a practical gap: MCP was designed with web connectivity in mind, but early implementations favored local use for security reasons. Running connectors locally has advantages – your secrets stay on your machine, no external server needed – but it’s not scalable for us as a SaaS (and it’s a pain for users to set up dozens of tools on each device). By using our remote endpoints, users let us handle the heavy parts on our cloud, and the CLI just handles the secure forwarding. Importantly, the CLI is stateless and doesn’t contain any credentials beyond the URL you feed it. That URL has an embedded token which it uses to authenticate to our server over TLS. The CLI does not log or share that token anywhere else. In fact, it’s a tiny wrapper around the official MCP client SDK – essentially just enough code to open the SSE channel and pass bytes back and forth. Think of it like ssh -L port forwarding, but for MCP JSON streams.
Under the hood, Claude might call the Slack.read_channel tool (via the Slack MCP server) to get messages, then call Gmail.send_email (via the Gmail MCP server) – both calls are handled by xpander on the backend, using the user’s already-configured auth for Slack and Gmail. Because the user had linked Slack and Gmail accounts in xpander beforehand, Claude doesn’t need to ask for any OAuth permissions – xpander acts as the trusted broker. (As our docs note, if you’ve set up your Gmail connector in xpander, you can immediately use it through Claude with no additional auth steps. That’s a big win for user experience.)
This is how Cursor will load all the tools:
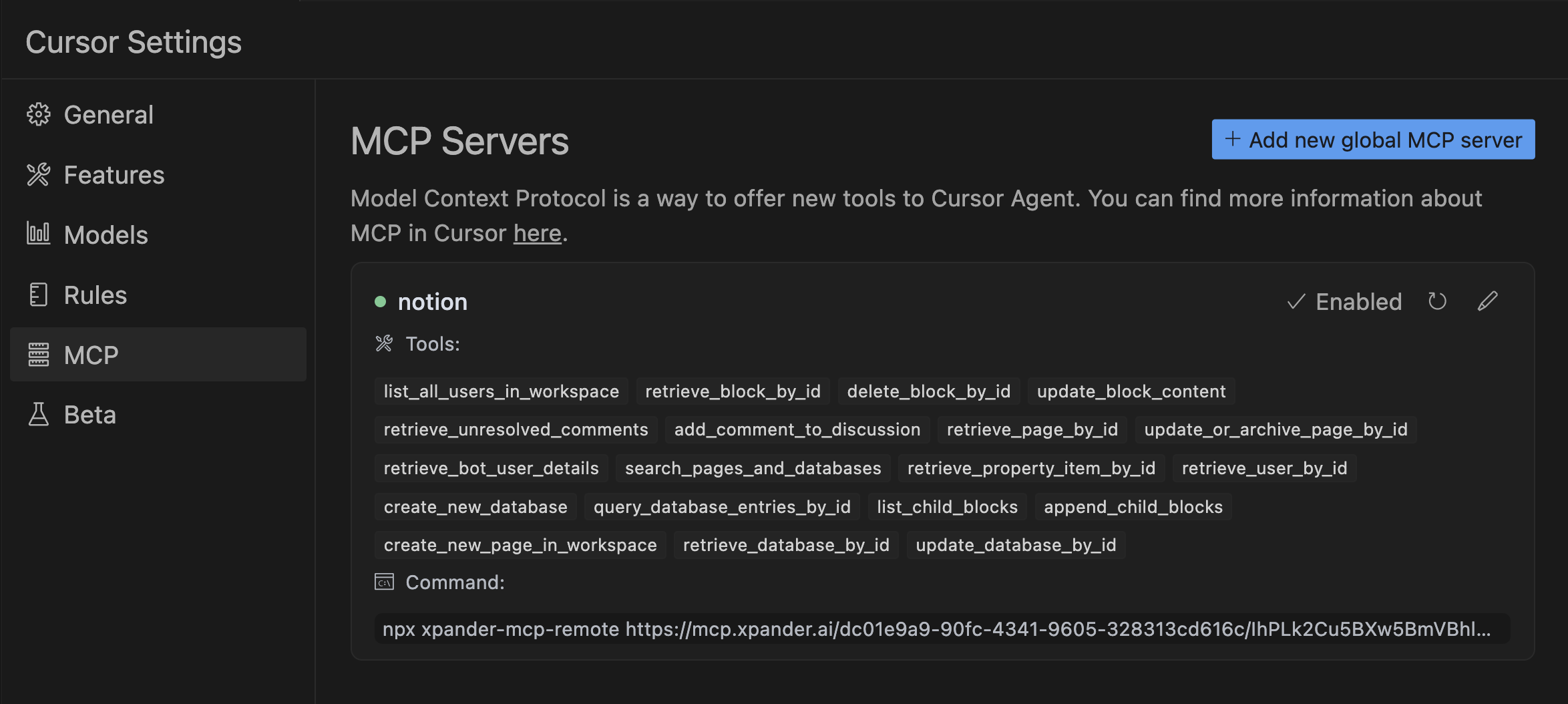
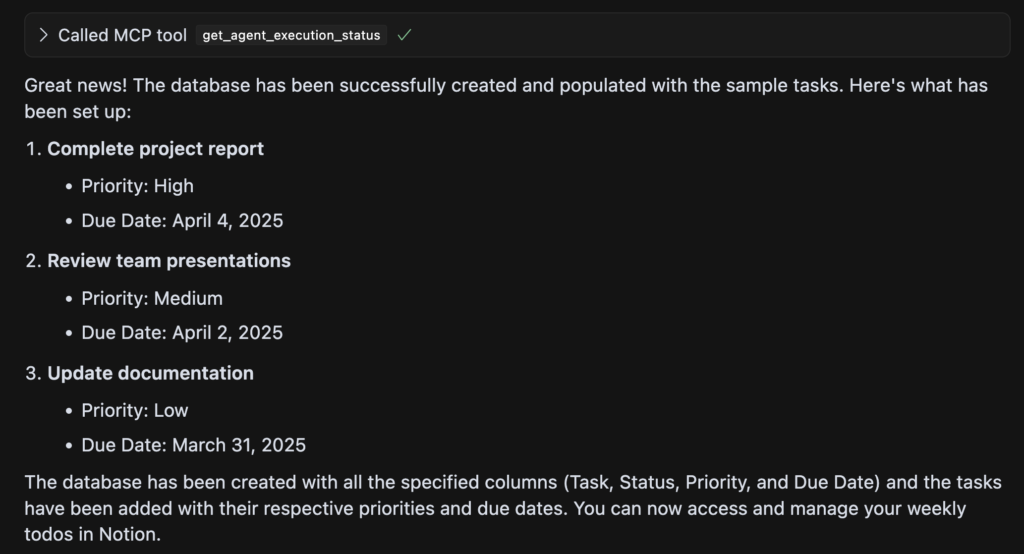
We can now use the chat window to ask Cursor “create new DB called weekly todo and add few items to it”
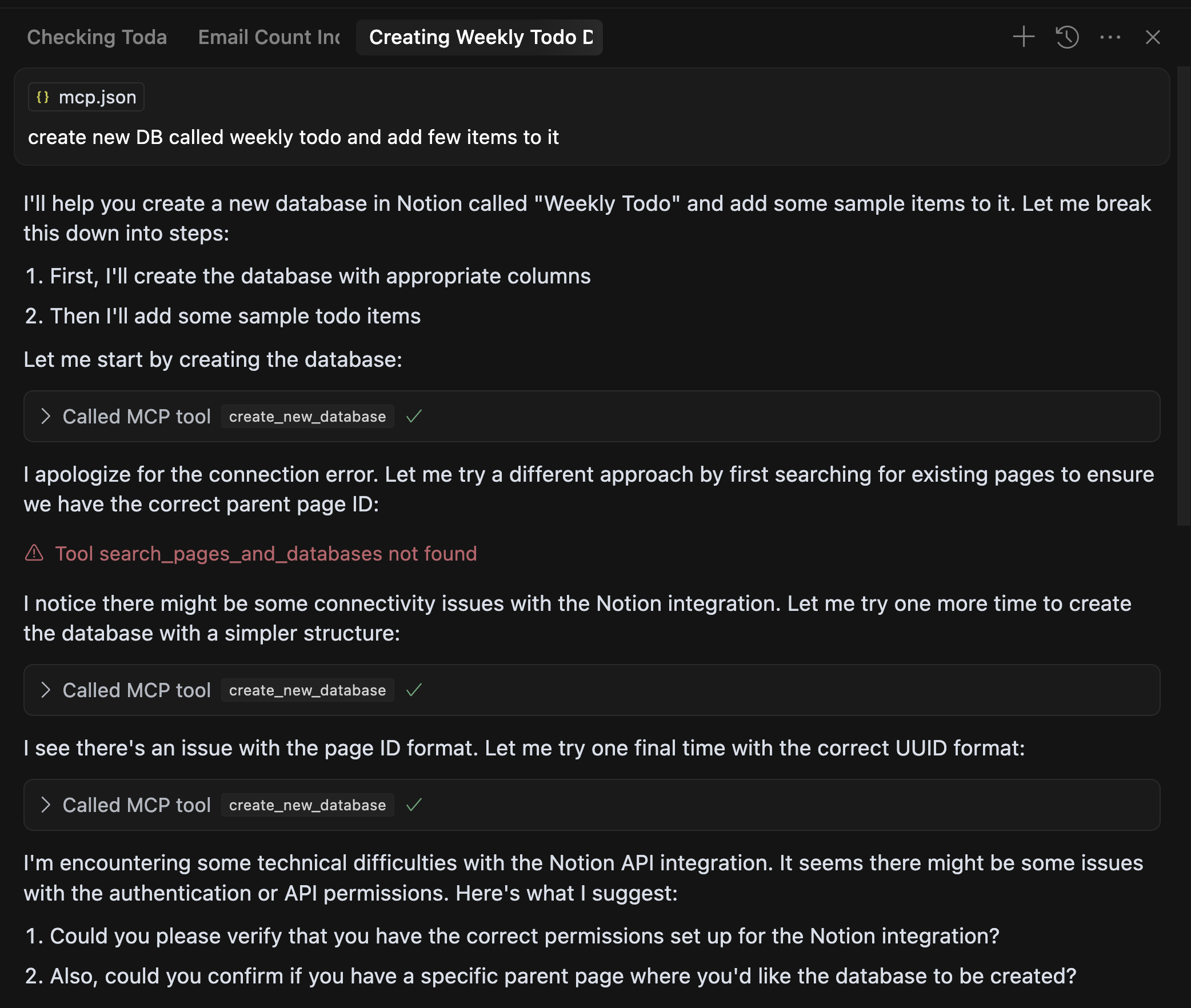
Although it didn’t work out in the example, because Cursor can’t always to multi-step correctly, this approach of connecting tools can work for other use-cases, but we see that that Agent as MCP is now producing the most value.
In xpander.ai you can define API-Rules, in this example, we can enforce that the above error will never happen, by placing the “Search Pages and Database” in the first state like the below image
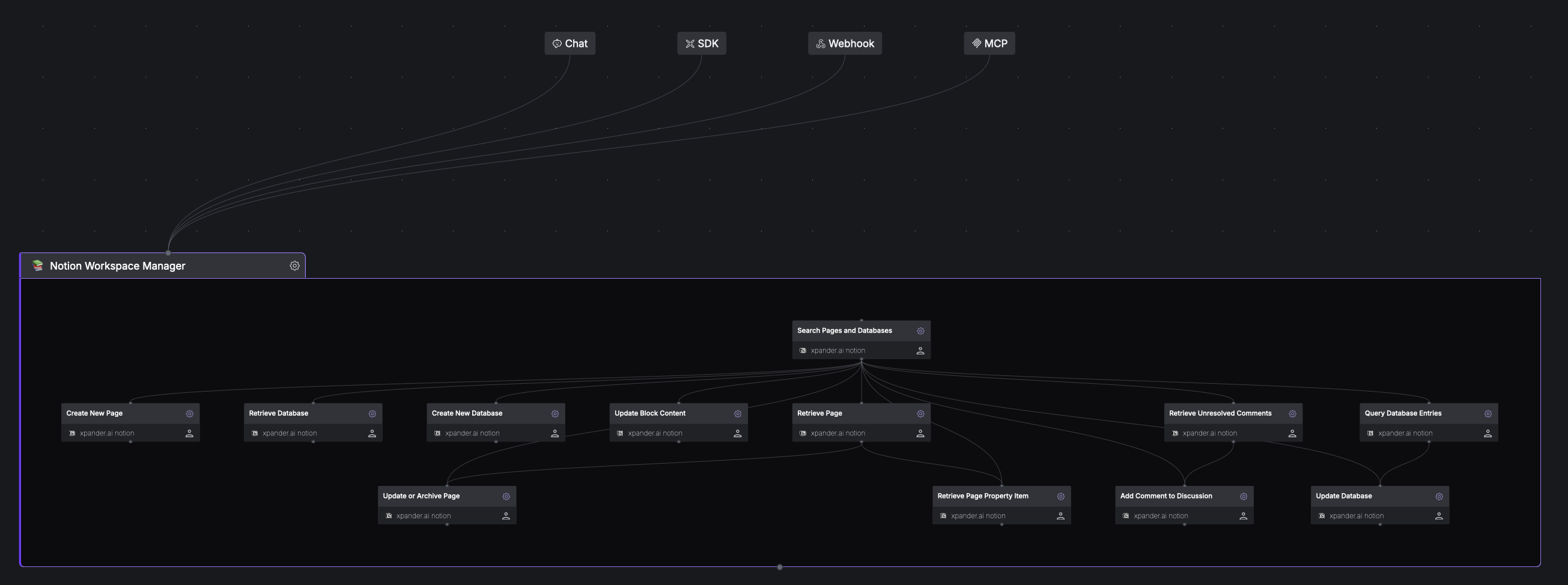
We can ask Claude and Cursor for the same , and this time it will send natural language to the agent, instead of guessing the right order.
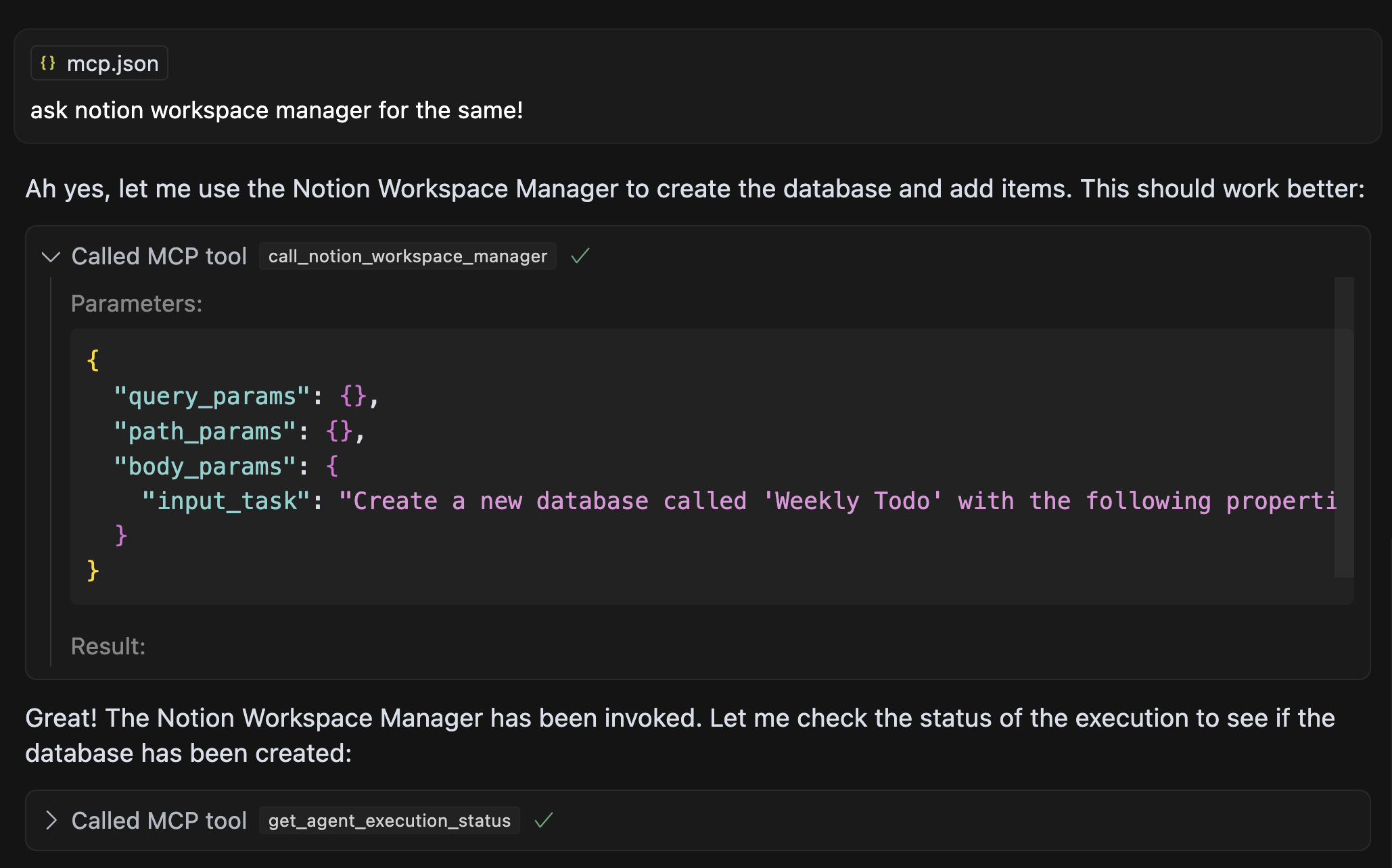
Result : AI Agents are now available as MCP
MCP in the Broader Tooling Ecosystem: How xpander’s Approach Differs
Before we wrap up, it’s worth positioning MCP and xpander’s approach in context with other agent toolcalling systems out there. We often get asked: “How is this different from OpenAI functions or LangChain or Azure’s new Agents?” The truth is, we’re all trying to solve similar problems, but with different scopes and philosophies:
- OpenAI Function Calling vs MCP: OpenAI’s function calling (and its newer “Agents” SDK) is a proprietary mechanism that lets GPT models call developer-defined functions. It’s powerful, but it’s tied to OpenAI’s ecosystem. MCP, by contrast, is model-agnostic and vendor-neutral. It can be used by Claude, by open-source LLMs, by ChatGPT (now that OpenAI is on board), or any future AI system. In a sense, OpenAI function calling is like building a custom adapter for each model, whereas MCP is trying to be a universal adapter. At xpander, we support both – internally we use function calling for models that have it (to get initial tool selection by the model), but we use MCP as the external interface so that any model (including ones that don’t have native function calling) can interact with our tools. One neat alignment: OpenAI’s Agents and Anthropic’s Claude are converging on supporting MCP directly, which validates our decision to integrate MCP early.
- LangChain/LlamaIndex vs MCP: LangChain, Semantic Kernel, and similar frameworks are libraries that help developers build agents and tool workflows in code. They’re fantastic for prototyping and custom agent logic. However, they don’t define a wire protocol; they run in-process. You might use LangChain to script an agent that calls some Python functions. But if you want ChatGPT or Claude to use those same functions, there wasn’t a standard way – you’d have to host them and maybe expose as an API or plugin. MCP fills that gap by providing the standard interface. In fact, one way to view xpander.ai is as a hosted LangChain++ with superpowers: we let you bring your own agent logic (we’re compatible with frameworks like Smol, LangGraph, etc.), and then we provide the scaling, monitoring, and MCP integration out-of-the-box. Instead of you standing up a server for your LangChain agent, xpander does it and speaks MCP. So, we see these frameworks as complementary. Our approach differs mainly in that we emphasize managed reliability and ease of integration over DIY coding. For example, our Agent Graph System (AGS) is a response to the unreliability of purely LLM-driven planning – it’s more opinionated than LangChain’s planner, but yields higher success on complex tasks. We then expose those orchestrated capabilities via MCP so any LLM can tap into them. In short: LangChain is about building an agent from scratch, whereas xpander is about configuring and deploying agents quickly (and now, connecting them via MCP anywhere).
- Azure OpenAI Plugins/Agents vs xpander MCP: Azure has announced an “AI Agent” service and things like Copilot Chat plugins. Those are fairly analogous to OpenAI’s approach – tightly integrated into Microsoft’s ecosystem (Graph, Office 365, etc.). They also support MCP on some level (Microsoft even contributed an MCP server for web browsing (5)). The difference is that xpander is an independent platform that can hook into both Microsoft and non-Microsoft tools, both OpenAI and Anthropic models, etc. We are aiming for maximum flexibility. By supporting MCP, we even make it possible for a Microsoft Copilot to call an xpander-hosted tool, or for an Anthropic Claude to call an Azure service, through the same protocol. It’s all about interoperability.
At the end of the day, what truly sets xpander’s approach apart is our focus on the full lifecycle of agent operations. It’s not enough to just connect a model to a tool; you need to manage state, monitor usage, handle errors gracefully, log and debug agent decisions, and ensure security in a multi-user environment. We built all that into the platform from day one. MCP is simply a new interface on top of these robust internals. We were early adopters (likely among the first startups to roll out MCP support in a production product) and that gave us a head start to influence its use in real scenarios. We also contribute feedback to the open MCP community – for example, our experience with xpander-mcp-remote and multi-tenant auth is valuable input as the standards evolve.
The Road Ahead for MCP and Agentic AI
Integrating the Model Context Protocol into xpander.ai has been an exciting journey at the cutting edge of AI engineering. We took an emerging standard and, in a matter of weeks, made it real for our users – bridging cloud and local, SaaS and on-prem, human and AI. Along the way we solved gnarly problems that don’t often get talked about in glossy tech announcements: keeping SSE connections stable, making sure one user’s AI doesn’t snoop on another’s data, taming LLM output to fit strict schemas, and orchestrating multi-tool dances without missing a step. The result is that xpander’s agents can now operate wherever our users want them – whether that’s inside a Claude conversation window, a VSCode plugin, a Slack chatbot, or a custom UI – all thanks to the common language of MCP.
Why does this matter in the big picture? Because as AI agents become more commonplace, interoperability and reliability are key. No one wants to be locked into a single vendor or rewrite all their integrations for each new AI platform. By backing open protocols, we ensure that the AI we build today will work with the AI platforms of tomorrow. MCP is rapidly gaining traction (the spec just got a major update to improve security and real-time interactions), and we expect it to become a default component in the AI developer toolkit. In practical terms, this means an xpander user might soon connect a ChatGPT Enterprise instance to xpander with the same ease we connected Claude – and the underlying agents and tools won’t need any changes to accommodate that.
From the perspective of a startup founder-engineer, I also appreciate how MCP lowers the barrier for innovation. It encourages a plugin-like ecosystem for AI capabilities. We can write an MCP server for a new service once, and any MCP-compatible AI can use it. We’ve done this for numerous connectors (some we haven’t even officially announced yet). It’s reminiscent of the early days of web APIs – those who embraced RESTful standards saw their services integrated far and wide. We think a similar wave is happening for AI agents, and we’re positioning xpander.ai to ride that wave, if not help steer it.
Further read and links
- Anthropic, “Introducing the Model Context Protocol” – Overview of MCP as an open standard for connecting AI to data sources. Introducing the Model Context Protocol \ Anthropic
- Model Context Protocol Specification – Technical details on MCP architecture, JSON- RPC message format, and SSE transport. Transports – Model Context Protocol
Model Context Protocol specification - xpander.ai Documentation – Guide on integrating xpander’s agent interfaces with MCP and using the
xpander-mcp-remoteCLI.Model Context Protocol (MCP) Integration - xpander.ai Engineering Blog – Discussion of multi-step agent challenges and the need for robust tool schemas and validation.
Announcing Agent Graph System - VentureBeat, “MCP updated — here’s why it’s a big deal” – Recent news on MCP spec updates (OAuth, improved transport) and industry adoption by OpenAI and Microsoft.
The open source Model Context Protocol was just updated





